




Open a jupyter notebook to follow along. The following code blocks are cells in an ipynb notebook.
Pre-requisites:
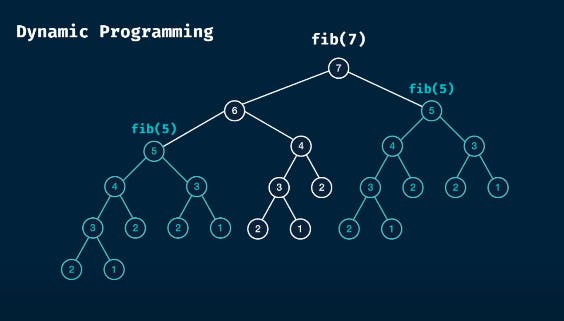
You must know how to find the n-th term of the Fibonacci sequence using recursion.
Fibonacci
Link to video.
from timeit import timeit
Now lets first make the standard recursive function.

def fibo(n: int) -> int:
# without memoization
if n <= 2:
return 1
return fibo(n-1) + fibo(n-2)
Now let's try to use memoization, that will reduce the time complexity to n.

def memo_fibo(n: int, memo: dict = {}) -> int:
# with memoization
if n in memo:
return memo[n]
if n <= 2:
return 1
memo[n] = memo_fibo(n-1, memo) + memo_fibo(n-2, memo)
return memo[n]
Let us set a value of n (the term of the Fibonacci sequence we want to find )
n = 40
Let us execute the normal way. (Here I have used a magic command of Jupyter Notebook, to find the execution time)
%%timeit -n 1 -r 10
fibo(n)
33.4 s ± 257 ms per loop (mean ± std. dev. of 10 runs, 1 loop each)
Now let us execute the function that used the memo.
%%timeit -n 1 -r 10
memo_fibo(n)
The slowest run took 86.52 times longer than the fastest. This could mean that an intermediate result is being cached.
3.6 µs ± 9.59 µs per loop (mean ± std. dev. of 10 runs, 1 loop each)
The difference is stark. From 33.4 s to 3.6 µs.
Thus you see, how using memoization brings in a huge difference in time of execution.
The name 'Fibonacci' is due to a 13th-century Italian mathematician Leonardo of Pisa, who later came to be known as Fibonacci.
However, what we popularly call 'Fibonacci numbers' find their earliest mention in the 2nd century BCE work of Indian thinker Acharya Pingala.